Grappling with infinity in constraint solvers
In 2016, I created a programming language called Sentient. Since then, I’ve had time to reflect and think about the language. This series is about that.
Many constraint-satisfaction problems deal with infinity in some shape or form. Even rudimentary problems, like "Find two integers that sum to 10". Solutions include:
- (4, 6)
- (-7, 17)
- (-1953856112, 1953856122)
In fact, there are infinitely many solutions and infinitely many pairs of integers to test. Here’s a Sentient program to solve this problem:
int a, b;invariant a + b == 10;expose a, b;A Sentient program to find integers that sum to 10
We can run this with the --number 0 option,
to continuously find solutions:
After a few seconds this program terminates which seems wrong. Why should a problem that has infinitely many solutions ever terminate? Shouldn’t it run forever?
The simple answer is that integers in Sentient aren’t really integers as far as
the mathematical definition is concerned. Their magnitude is limited by how
many bits represent them. By default this is
8 but can be specified, e.g. int9, int32
In many cases this is fine. We can pick a number of bits that’s ‘big enough’ and not worry about it. But other times it’s not fine. We often want to start small and work our way up to larger representations, but that means restarting the program each time.
For some problems, solutions are extremely rare (or non-existent) and it could take weeks or months for Sentient to find one. In these cases, it makes sense to start with small representations and progressively rule our search spaces of increasing size.
Unfortunately, when a program is restarted, we lose its progress. Regions that
were already explored are explored again. If we increase int to int9,
Sentient finds new solutions but it also finds all the same solutions again.
This is wasteful.
We could compensate by adding a constraint:
int9 a, b;invariant a < -128 || a > 127 || b < -128 || b > 127;# ...Eliminating the region we’ve already explored
But this becomes unwieldy, and for many problems, isn’t easy to specify. It’s also a manual process and therefore error-prone. Ideally, Sentient would offer first-class support for something like this. I have some ideas about how that might work.
Approximations
I’ve found a useful way to think about this is in terms of approximations. An eight-bit integer is really an approximation of the mathematical (infinite) version of an integer. Its domain is finite but as long as we stay within bounds, it behaves in the same way.
Most of the time when we write computer programs we don’t have to think about this because we deal with concretions. Variables are assigned concrete values and, provided we stay within range without overflowing, everything checks out.
In our case, variables are ‘symbolic’. We
don’t actually assign values to int a, b, we just tell Sentient they exist and
specify some constraints. Its job is to discover values for a, b, but it has
to work with something tangible. It can’t reason about infinity.
Why can’t Sentient reason about infinity?
Technically it could but currently, its implementation closely relates to the mechanism it uses for solving. Programs are compiled to instances of SAT which, by definition, are boolean equations that comprise finitely many variables and clauses.
This doesn’t have to be the case, though. Sentient could abstract over these equations and automatically introduce new variables to represent larger integers.
Actually, Sentient does something similar to
this for the --number option.
Sentient finds multiple solutions to problems by repeatedly solving the same
equation. It introduces a new clause each time to ban the solution it just
found.
Could we dynamically change the size of representations?
We could, but it’s not obvious how to do this. If a program declares multiple
integers, should we change their number of bits all at once or one by one? For
example, should we increase a and b to int9 in one go, or a followed by
b ?
For some problems, there could by differences in magnitude that are important:
int a, b;int15 target;invariant a * b == target;expose a, b, target;This program contains implicit knowledge
that multiplying two numbers in the range -128 to 127 results in a number in
the range -16,384 to 16,383. Every time we increase a and b’s
representation by one bit we should probably increase target’s by two.
What’s more, we haven’t considered more complex cases. What about arrays of integers or arrays of arrays? We also need to consider how Sentient communicates where it’s up to. Which regions of search space has it exhausted so far?
More infinity
Before we try to answer some of these questions, let’s first consider other places infinity might crop up. There’s an excellent series on Numberphile about the problem of finding three cubes that sum to a target number. Let’s use that to help reason.
Here’s a Sentient program to solve this problem:
int a, b, c, target;invariant a.cube + b.cube + c.cube == target;expose a, b, c, target;A program to find three cubes that sum to a target
Firstly, let’s say we want to generalise our program further. Instead of summing
three cubes together, it’d be nice if we were able to write a program that sums
N cubes. We could assign N at runtime if we want or leave it unspecified.
This isn’t valid syntax, but such a program might look like:
array<int> numbers;int target;invariant numbers.map(*cube).sum == target;expose numbers, target;A program to find N cubes that sum to a target
Furthermore, why should the exponent be fixed? It’d be wonderful if that too could be assigned at runtime or left unspecified for an extra degree of freedom.
That program might look like this:
array<int> numbers;int target, exp;invariant numbers.map(*pow, exp).sum == target;expose numbers, target, exp;A program to find N numbers raised to an exponent that sum to a target
Perhaps this is too generic, but consider this: In just four lines, we’d be able to write a program that can solve a broad class of diophantine equations. I find this tantalising. It would be a triumph of our ability to communicate intention to the machine.
How does this fit with approximations?
If we consider these cases in the context of approximation, a fixed-size array could be seen as an approximation of a general array of unlimited size. We could approximate a general array by running multiple versions of our program with different sizes.
There are infinitely many array sizes to try and infinitely many exponents. These cases differ slightly from before because there’s no overlap in search space. Nine-bit integers contain all the eight-bit integers, but ‘squares’ and ‘cubes’ are distinct problems.
Multi-dimensional space
For each of these approximations, we can think of them as defining a dimension
in space. For example, here’s a two-dimensional space for integers a and b:
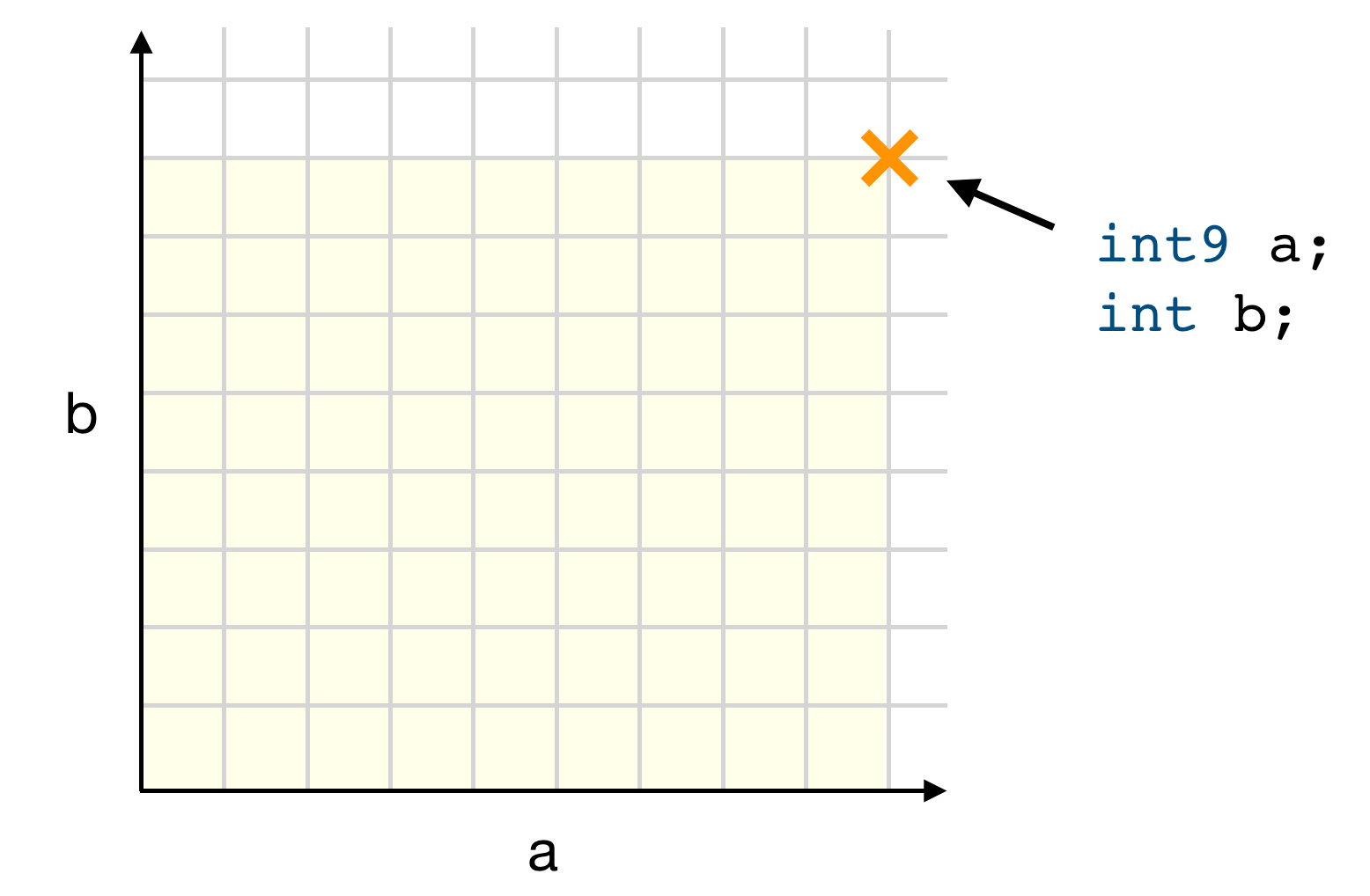
The highlighted point is an instance of a
Sentient program with integers a and b approximated with nine and eight
bits, respectively. The shaded region shows the space being considered which
includes integers with fewer bits. The axes go to infinity.
Each time we approximate an integer, this adds a new dimensions to our space. If we run a Sentient program multiple times with different approximations, we can think of this as defining a walk or a path through this multi-dimensional space.
Infinite-dimensional space
Our extremely general program above contains this line:
array<int> numbers;Here there are two kinds of infinity. Arrays can have unlimited size and integers can be arbitrarily large. This is problematic because we first need to approximate the size of the array and then approximate the integers within that array.
The result of these two degrees of freedom is an infinite dimensional space with a dimension for every possible size of array. The nth dimension in this space defines how many bits are used to approximate the integer at position n in the array.
As we add more approximations, these spaces are compounded and this spatial metaphor starts to fall apart. I’m not sure whether it’s useful to think about approximations in this way when we go above a small number of dimensions.
Incrementality
Now let’s turn back to the question of how to change approximations over time. There doesn’t seem to be an obvious approach other than something naive like round-robin. Approximations with overlapping / non-overlapping spaces complicate things further.
It seems to me the most robust way to do this is to delegate these decisions to the programmer. Define a protocol so that a program can determine how approximations should change at various stages during the search.
For example, our program that "finds two integers that sum to ten" could initially call an external program that instructs it how many bits to use for its approximations. Once the search space is exhausted, it could ask the program what to do next:
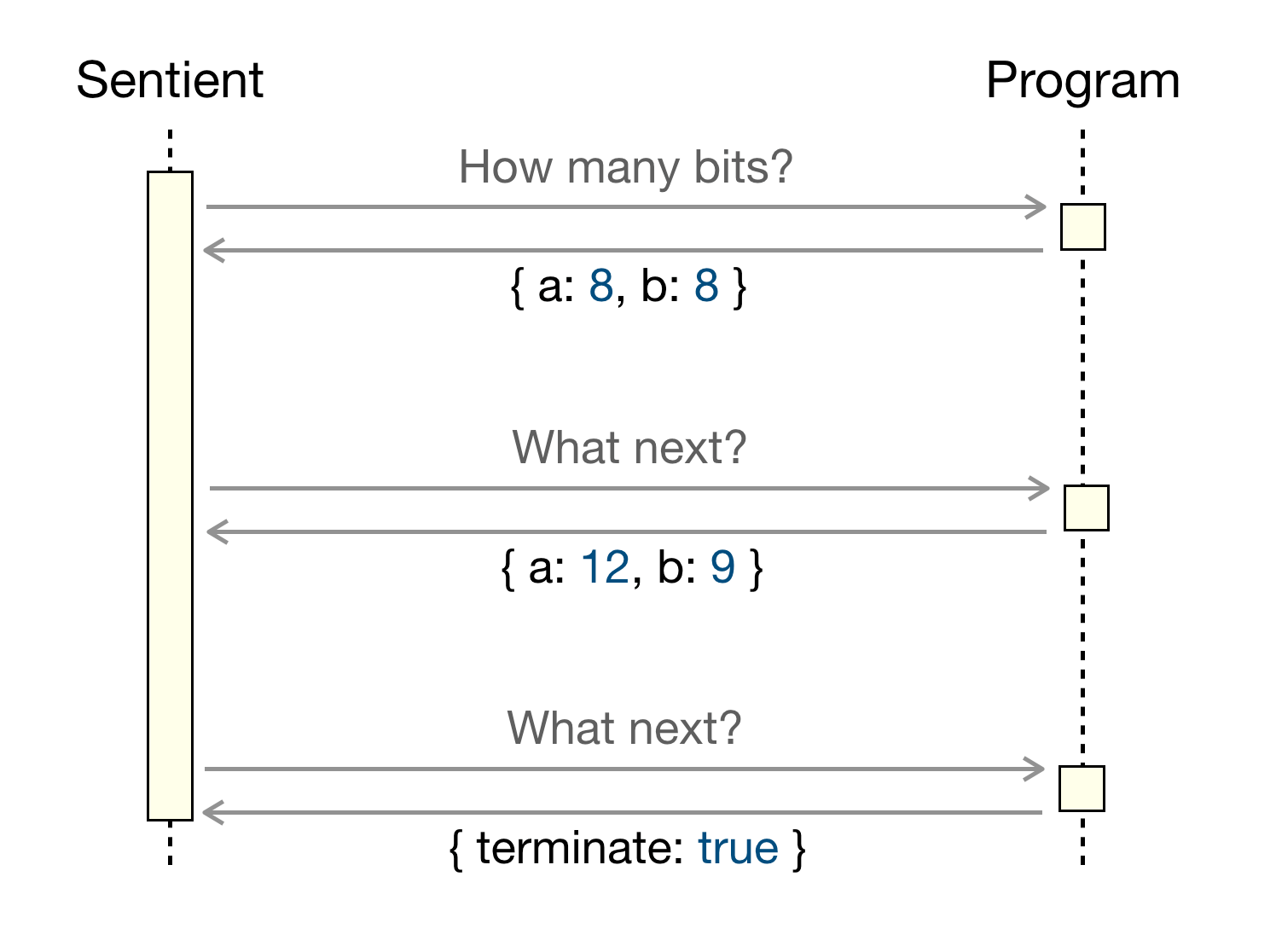
The protocol could even allow Sentient to spawn new processes and search distinct spaces in parallel. For example, it could search for solutions to the ‘squares’ and ‘cubes’ problems concurrently while controlling approximations in each instance.
Incremental SAT
In the world of SAT solving, a mechanism already exists for communicating with a solver during its search. It’s called the ‘Re-entrant Incremental Satisfiability Application Program Interface’ and is referred to by its reverse acronym ‘IPASIR’.
In fact, I wrote a Rust crate not too long ago for communicating via this interface. The advantage of using it is to speed up solving problems that have been modified in small ways without having to restart the search from scratch each time:
It is possible to solve such problems independently, however this might be very inefficient compared to an incremental SAT solver, which can reuse knowledge acquired while solving the previous instances. – SAT Race 2015 (abbreviated)
At present, Sentient doesn’t use IPASIR at all. It was fairly new when I wrote the language but has wider adoption today. At the very least, it would speed up searching for multiple solutions to problems, but I think it could help with approximations, too.
Ideally, a single instance of a SAT problem would live for the duration of a Sentient program. As approximations change, so too would the underlying boolean equation. That would allow a maximal amount of information or ‘knowledge’ to be reused.
Representations
There are limitations on what you can do with IPASIR, otherwise it would be very difficult for solvers to reuse knowledge from previous searches. For example, you can’t remove clauses but you can instead make ‘assumptions’ that are short-lived.
Some thought would need to go into how to represent approximations in a way
that allows them to change later. If we go from int to int9, we don’t want
to have to throw everything out. It should be possible for approximations to
‘grow’ or ‘shrink’.
All of the operations we apply to integers need to be able to cope with a changing number of bits. For example, integer addition is modelled after ripple-carry adders. Its clauses in the boolean equation would need to use assumptions in clever ways.
It may even be there are efficiency gains if we know in advance how approximations will change. If they only ever grow, and by precisely two bits each time, perhaps there’s a more efficient way to structure these equations. I’m not sure.
NP-hard problems
One final thought about incrementality is it would allow Sentient to reach the dizzying heights of being able to solve NP-hard problems. At present, Sentient can’t solve optimisation problems. It doesn’t specifically search for minimums or maximums.
However, you can effectively do this by running the same program multiple times. For example, let’s say you want to find two numbers that sum to ten such that the sum of their squares is minimised. You could write a program like this:
int a, b, max;sum = a.square + b.square;invariant a + b == 10;invariant sum < max;expose a, b, sum, max;Solving an optimisation problem with Sentient
You could then run this multiple times, reducing max until there are no
solutions:
Finding the optimal solution over repeated runs
I’m not sure whether my definition of approximations extends to optimisation problems but there’s definitely an opportunity to use incrementality in a number of useful ways.
Turing-completeness
While we’re on the topic of NP-hard problems, it’s probably worth saying a few things about computability and Turing completeness. On the Sentient website I wrote this:
In fact, Sentient isn’t Turing complete. It is a Total programming language – it is fully decidable and does not suffer the Halting problem. That drastically limits what it can do. For example, recursive function calls are not supported and never will be.
In fact, through the lens of approximations, it may be possible for Sentient to become Turing complete. At present, Sentient doesn’t support recursive function calls:
int a;function factorial (n) { return n > 0 ? n * factorial(n - 1) : 1;};invariant a.factorial > 150;expose a;A hypothetical Sentient program using recursion
A recursive function call can be approximated by limiting its depth of
recursion. For example, if factorial were approximated with a depth of 5 (or
less), it wouldn’t find a solution but improving this to 6 would. Similarly, you
can’t do this at the moment:
int a;sum = 0;a.times(function^ () { sum += 3; });invariant sum > 10;expose a;Another hypothetical program that isn’t allowed
Sentient throws an error when you try to run this program:
Called ‘times’ with ‘a’ but ‘times’ only supports integer literals (arg #0)
This isn’t supported because a is
‘symbolic’. Sentient is unable to compile this program to a boolean equation
because the size of that equation can’t be determined. Its structure isn’t
fixed. The #times method only works with ‘integer literals’ like 5.
Again, we could solve this problem with approximations by limiting the value
for a.
Loop unrolling
This technique is already used in various forms. Compilers frequently unroll loops and recursive function calls for performance reasons. Model checkers perform static analysis to check invariants, often using techniques established in Hoare logic.
I see loop unrolling as another kind of approximation. Recursive functions could be identified through static analysis and an external program could decide how many calls are allowed for the current instance of the search.
In theory, these techniques would allow Sentient to be Turing complete in a sense. This combined with incremental SAT could make for an extremely powerful system. The ability to solve problems relating to arbitrary Turing machines would be amazing.
Where next?
I’m not sure. I’d like to play with these ideas more and perhaps some day incorporate them into Sentient or something else. There are clearly challenges with incrementality and interface design but I think I’m on the right track.
This is the first in-depth article I’ve written about Sentient and constraint solving but hopefully there’s more to come. I’ll announce future updates on Twitter if you want to hear more. Follows are always appreciated. Thanks.